
Office of the Assistant Secretary for Planning and Evaluation
Contract: HHS-100-97-0012, Delivery Order No. 7
The Lewin Group, Inc.
March 18, 1998
"I. Introduction
| This paper offers a guide for evaluating activities designed to increase organ donation. While the organ donation community has been very active in attempts to increase organ donation, there has not been a concerted effort to determine the best methodologies for evaluating these activities. Although many activities have been evaluated at some level (e.g., counting donor card signatures), there is relatively little understanding about how these activities relate to the goal of increasing the number of organs available for transplantation. (Appendix B provides an overview of evaluations of organ donation activities.) Well-planned and methodologically sound evaluations, coupled with program goals and timeframes, provide the cornerstone for understanding program effectiveness. Rigorous evaluations of activities designed to increase organ donation will better inform resource allocation among alternative and complementary programs.
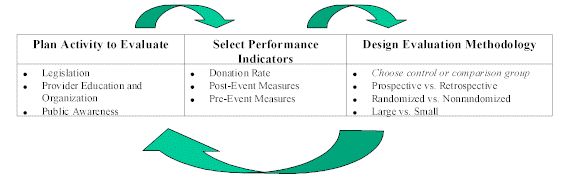
The organ donation community is not alone in its intent to develop methodologically sound strategies for evaluating its activities. Recently, similar evaluation efforts have focused on evaluating such behavior modification programs as: smoking and substance abuse prevention and recovery programs, programs to increase use of mammography and other forms of cancer screening, physical activity promotion efforts, occupational health activities, and other health education programs. For example, a review of AIDS education program evaluations in 1990 found that many of the evaluations failed to use standard evaluation designs (e.g., time series) and had no information linking changes in knowledge to behavior changes (Forst 1990). Other behavioral modification evaluations have been more successful in applying rigorous evaluation designs. (Appendix C provides an overview of evaluations in these areas). This paper outlines the three essential components of a successful evaluation, namely: 1) rigorous evaluation methodology, 2) tested performance indicators, and 3) an activity to evaluate that is related to the ultimate goal of the program. Exhibit 1 provides an overview of these elements and how they inform and influence each other. The paper begins with an overview of evaluation methods and a discussion of the relative merits of such methods. It then turns to a discussion of the performance indicators appropriate for organ donation activities. Finally, the paper presents examples of evaluation elements for selected types of organ donation activities. Exhibit 1: Overview of Evaluation Planning Source: Lewin, 1998 |
II. Evaluation Methodology
Despite the diversity of design, costs, and other factors, the aim of evaluation methods in use today is essentially the same, i.e., to assess the effect of an intervention on one group compared to the effect of a different intervention (or no intervention) on another group. By definition, all evaluations have a control or comparison group. Exhibit 2 depicts a basic framework for considering the methodological rigor of evaluation types, their respective study elements, and examples of organ donation activity evaluations.
The evaluation types in Exhibit 2 are listed in rough order of most to least scientifically rigorous for internal validity, (i.e., for accurately representing the causal relationship between an intervention and an outcome in the particular circumstances of a study). This ordering of methods assumes that each study is properly designed and conducted; a poorly conducted large RCT may yield weaker findings than a well conducted study that is lower on the design hierarchy. This list is representative; there are other variations of these methodologic designs and some investigators use different terminology for certain methods (Appendix A contains definitions of the evaluation types listed in Exhibit 2).
As Exhibit 2 depicts, every evaluation has strengths and weaknesses. There are typically trade-offs involving rigor, cost, and feasibility. The importance of this trade-off depends largely on the activity under study and the goals and resources of the organization conducting the evaluation. For example, it is possible to design a prospective study to evaluate the effect of a national media campaign on actual organ donation rates. However, the time and resources (e.g., money) needed to track millions of people over time to capture what may be small differences in donation rates might not be feasible. A prospective evaluation design may more appropriately be used to assess post-event activities because fewer people (i.e., only those who become potential donors) have to be tracked over a shorter period of time to capture a change in the donation rate. For example, a prospective study might feasibly assess decoupling the discussion of organ donation from the announcement of brain death on consent rates.
Given resource and time constraints, and the difficulties associated with randomizing and perfectly controlling "real-world" studies, it may not be possible, and is often not practical to conduct a randomized controlled study. However, all evaluations can include elements that strengthen the methodology of the study and produce more rigorous results. For example, a more valid comparison group often can improve study designs. In a time-series study one group (e.g., a hospital) is measured at baseline (e.g., consent rate, donation rate) and subjected to an intervention (e.g., an in-service provider education program) and re-measured at several intervals to assess changes in performance indicators. A more rigorous control would be an external control, for example a hospital not receiving the in-service program. The control hospital is subject to the same external influences as the study hospital (e.g., a concurrent mass media campaign) and thus the effects of the intervention can be measured more accurately. Examples from the behavioral literature provide insight on how to select and randomize control groups for "health behavior interventions" similar to changing personal behavior with regard to organ donation (Appendix C).
Exhibit 2: General Strengths and Weaknesses of Evaluation Types
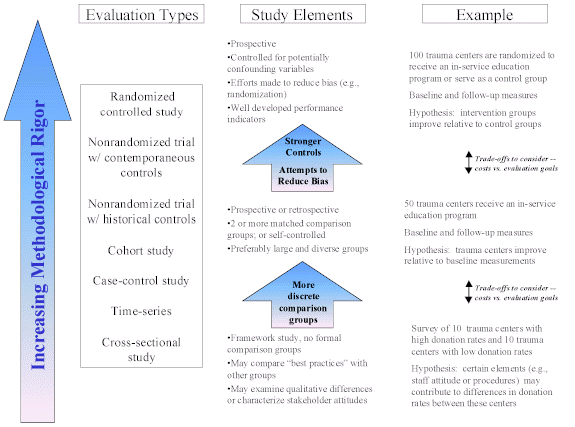
Source: Lewin, 1998
The following general guidelines are helpful for weighing the relative rigor of alternative types of controlled studies.
-
Randomized studies are stronger than non-randomized studies.
Randomized studies require the assignment of subjects to intervention and control groups based on a chance distribution. This technique is used to diminish subject selection bias in controlled studies.
-
Prospective studies are stronger than retrospective studies.
In a prospective study, the investigators conduct an investigation on a group of subjects and analyze the outcomes. In a retrospective study, investigators select groups of subjects who have already been subject to an intervention and analyze how the intervention relates to the outcomes.
- Large studies are stronger than small studies.
The sample size of a study should be large enough to have an acceptable probability of detecting a difference in outcomes, if such a difference truly exists, between the experimental and control groups attributable to the intervention being evaluated. Although larger studies increase the statistical power of the evaluation, there is a point beyond which there are diminishing returns and studies may become unnecessarily costly and inefficient.
- Contemporaneous controls are stronger than historical ones.
A contemporaneous control group exists when the results of an intervention group and a control group are compared over the same time period. An historical control group exists when the results of an intervention group are compared with the results of a control group observed at some previous time.
- External controls (multiple-group designs) are stronger than self-controls (one-group designs).
A multiple-group design exists when comparisons are made between one group receiving the intervention and one group not receiving the intervention (control). A one-group design exists when the experience of a single group is compared before (control) and after an intervention.
III. Performance Indicators
Performance indicators shape an evaluation, and the choice of performance indicators impacts the resources required to conduct the study and the utility of the study results. For example, measuring changes in public awareness of organ donation activities may not ultimately provide insight on what impact the study activity had on donation rates. Because it is impossible to predict who might become a potential organ donor before the occurrence of a traumatic event, any activity targeted at the general public must cast a wide net in order to reach those few people who will become potential organ donors. The complexity of an evaluation increases because there are a wide variety of reasons that potential donors do not become actual donors. These include not being identified as potential donors, caregivers not asking the families for permission to retrieve organs, families denying consent, and organs incorrectly deemed not transplantable (Gortmaker 1996). It is difficult to measure, with any statistical significance, the effect of a population-based program on the actual number of organs retrieved. The evaluation of population-based programs requires a careful selection of performance indicators based on the goals and resources of the organization conducting the evaluation.
To overcome limitations in measuring program effectiveness on actual organ retrieval, the organ donation community has used three related sets of performance indicators, each with varying
Exhibit 3: Sample Performance Indicators and Proximity to Donation
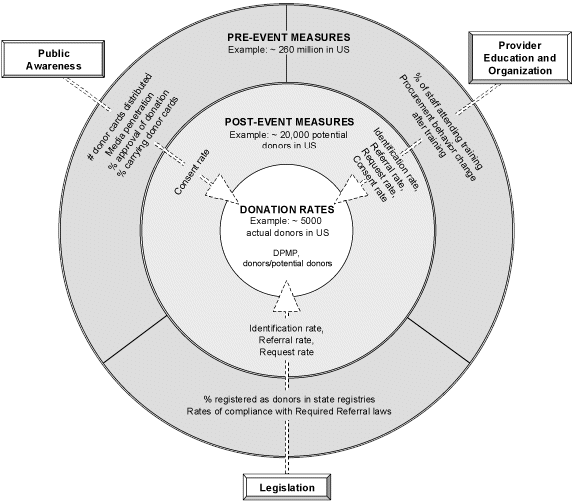
Source: Lewin, 1998
degrees of separation from the actual intended outcome of organ donation. The three types of measures are shown in Exhibit 3 as concentric circles, illustrating their relative proximity to the donation event. In addition, the US population is used as an example to depict the relative sizes of the populations captured in pre-event, post-event, and donation measures.
- Pre-event measures (represented by the outermost circle) are used to gauge effectiveness in increasing organ donation before an actual donation opportunity arises. The particular measures tend to be specific to the type of activity being performed. Compared to the other types of performance indicators, pre-event measures are most varied in nature, and are the farthest removed from the goal of measuring increased organ donation.
- Post-event measures (the middle circle) are commonly used in the organ donation community to measure the five crucial steps in organ retrieval after a potential donor situation has occurred. Chronologically, and with increasingly close ties to donation itself, these steps measure: 1) donor identification rate, 2) referral rate, 3) request rate, 4) consent rate, and 5) retrieval rate.
- Donation rates (the innermost circle) represent the most direct measure of the success of programs to increase the number of organs made available for donation.
A. Pre-Event Measures
Pre-event measures are most commonly used to evaluate activities that precede the trauma leading to brain death. Though frequently used as a proxy for program effectiveness on donation rates, they are process measures that serve as weak predictors of actual donation rates. A media campaign to increase the number of people who become organ donors when they renew their driver's licenses could be deemed successful if significantly more people signed donor cards than in months past. However, the link between the number of new licenses with organ donation approval and the donation rate is uncertain at best. A large follow-up study would be required to determine whether the process of signing a donor card had an impact on a family’s decision to donate organs. The link between pre-event measures and the primary goal of increasing organ donation is weak.
Many researchers are striving to improve pre-event measures by using these measures to assess the five stages of behavioral change that may lead to organ donation, i.e.: precontemplation, contemplation, preparation, action, and maintenance. These five stages of change were developed by Prochaska et al. (1983), originally in relation to smoking cessation programs. Studies in the areas of smoking cessation, mammography use, and weight loss programs have attempted to: 1) design measures for the stages of change, 2) determine if the stage of change correlates to success in the designated program, and 3) determine if activities can be implemented to improve cycling through the stages of change. These activities are evaluated relative to activities that were not specifically designed to promote cycling through stages of change. In the field of organ donation, these stages of change can be thought of as follows (Rohr, manuscript).
- Precontemplation: the person has not thought about donating organs.
- Contemplation: the person has thought about donating organs.
- Preparation: the person has made phone calls or requested information about organ donation.
- Action: the person has taken action to express his/her wishes about organ donation (e.g., signed a donor card, talked to a lawyer, discussed wishes with family).
- Maintenance: the person may occasionally remind or reinforce statement of wishes.
Multiple studies have indicated that familial consent for organ donation is one of the biggest barriers to donation. Other papers have shown that families are more likely to consent to donation if the deceased individuals have made their wishes known. Applying the stages of change methodology to measure progress towards action may be a useful indicator of outcomes. For example, stages of changes measures can be developed to determine whether a particular intervention moved people to sign donor cards and discuss organ donation with their families.
B. Post-Event Measures: Procurement Process Measures
Another group of broadly applicable measures relates to the various steps of the organ retrieval process: identification, referral, request, consent, and retrieval. Because these steps are more immediate to the act of donation, they are more meaningful, though still intermediate, indicators of the effectiveness of an organ donation activity. Also, because they are common to many different kinds of programs, they allow for more meaningful comparison across programs than pre-event measures. Each of the rates is described in detail below, with comments about potential uses.
1. Donor Identification Rate
The first step of the retrieval process is the recognition of a patient as a potential donor of viable organs. The identification rate is the number of potential donors identified divided by the total number of actual potential donors, as determined by medical record review (MRR).
- The identification rate is a potential measure of the effectiveness of provider education programs that seek to improve the ability of medical staff to properly recognize the fulfillment of donor criteria in a patient.
2. Referral Rate
The second step of the retrieval process is the referral of a potential donor to an OPO. The referral rate is the number of potential donors referred to an OPO divided by either total potential donors (determined by MRR) or by total identified donors (determined from hospital data).
- The referral rate can be used to evaluate the effectiveness of Required Referral and Required Request legislation. Although the intent of such legislation is to increase donation by involving expert OPO staff more frequently and earlier in the donation process, it is referral rate, rather than donation rate, that best indicates the impact of the legislation.
3. Request Rate
The third step of the retrieval process is the request made by hospital or OPO staff of the potential donor’s family. The request rate is the number of potential donors whose families are asked to donate divided either by total potential donors (determined by MRR) or by total identified or referred potential donors (determined from OPO or hospital data).
- The request rate can also be used to evaluate how well doctors and OPO staff respond to new Required Request legislation. While there are few intervening factors to make consent and donation themselves the primary measure of interest in an evaluation, the request rate, cross-referenced with these behaviors, is a useful tool for use in hospital and OPO-level quality review and intervention.
4. Consent Rate
The fourth step of the retrieval process is the consent granted for donation by the family of the potential donor. The consent rate is the number of consenting families of potential donors divided either by total potential donors (determined by MRR) or by total identified or referred potential donors (determined from OPO or hospital data).
- Requests decoupled from explanations of brain death, requests made in a private, quiet setting, and requests made of minority families by minority requestors have been correlated with higher consent and donation rates (e.g., Beasley 1997 and Kappel 1993). Because steps in the retrieval process after consent are affected largely by scientific matters such as tissue preservation and not by factors influenced by most donation activities (predisposition through request), consent rate is considered by many donation professionals to be the de facto outcome measure of programs to increase organ donation.
5. Retrieval Rate
The final step of the retrieval process is the retrieval of a viable organ from a donor. While regularly collected by OPOs to determine the efficiency of their retrieval processes, the primary factor in the difference between consent rate and donation rate lies in medical procedures to ensure tissue and organ viability.
- Due to scientific concerns such as tissue preservation and autopsy requests, the retrieval rate is not regularly used in place of either consent or donation in the evaluation of programs designed to increase donation.
C. Organ Donation Rates
The organ donation rate is a measure of the eventual goal of all donation-related activities: an increase in successful donations. Any activity that can be shown to independently increase donation is clearly successful.
1. Donors per Actual Potential Donors (as determined by medical record review)
The most precise definition of donation rate uses the actual number of potential donors as its denominator, whether or not the potential donors had actually been asked or even identified by procurement staff. The size of the potential donor pool is best calculated by retrospective medical record review (MRR).
- This measure is particularly useful for hospital and OPO-level evaluation, yielding measures not only of the donation rate but also of post-event measures, such as consent rate. However, the cost and time-intensive nature of the MRR is prohibitive for national-level donation studies.
2. Donors per Estimated Potential Donors (as determined by death certificate review)
A less expensive and faster alternative to estimating the potential donor pool involves using the number of deaths attributed by death certificate codes to causes that suggest potential donors. These data are relatively accessible from national mortality databases or state and local offices of vital statistics.
- The availability of death certificate data on the national level allows national rates to be determined consistently with state and local rates. Some researchers have expressed concern that the estimation is compromised by two problems: inconsistency in death coding patterns in different areas of the country and an insufficient definition of potential donors, particularly since there is no authoritative coding that assures potential for donation.
3. Donors per Million Population (DPMP)
The crudest outcome measure, and the one most widely used, is donors per million population (DPMP). It requires the assumption that potential donors are more or less equally distributed over a population, so that the population itself can be used as a rough proxy of the potential donor pool. The calculation of this measure is the easiest of the three outcome measures described here, requiring only census data and the number of donations in a specified geographical area.
- While the simplicity of this approach has made it the most recognized of measures, including use internationally and by the US DHHS in OPO certification, the use of unadjusted population size raises significant methodological problems. For example, any state with higher than average proportions of residents older than the allowable age for donation (e.g., Florida) or with a lower than average rate of trauma death will have an artificially high denominator in the DPMP rate, thus deflating its true procurement efficiency with "potential donors" who can’t be realized. Despite the ease of calculating DPMP, its lack of comparability across geographic borders compromises its utility for meaningful evaluation.
IV. Evaluating Activities
The final component required for successful evaluation concerns the nature of the program or activity itself. To date, the organ donation community has focused its efforts in three main areas: legislation, public awareness campaigns, and provider education and organization. Specific examples of each type of activity and sample evaluation techniques are discussed below.
A. Legislation
The role of the government in organ donation is significant. Aside from enforcing guidelines for defining brain death and thus potential donor status, governments plays have a role in the procurement process by legislating that certain steps, particularly referral and request, take place regularly, and that OPOs meet a minimum donation rate benchmark for certification. Government initiatives can also help increase donation by including donor information with tax forms or drivers license applications.
Sample hypothesis: State Required Referral laws will ensure that hospital staff contact the OPO when a potential donor has been identified.
Sample evaluation options:
- Compare referral and donation rates (DPMP) of states with Required Referral laws to states without Required Referral laws.
- Strengths: contemporaneous, non-random control group; large study size; links a post-event measure to the donation rate.
- Weaknesses: retrospective; potential underlying differences among compared states may bias results; DPMP may provide biased results if the underlying population in the compared states are different.
- Measure hospital referral rates after enactment of a required referral law.
- Strengths: post-event measure.
- Weaknesses: no control group – there is no way to know if any change in referral rates can be attributed to enactment of the law, or to other contemporaneous factors.
- Survey public opinion on organ donation in a given state before and after the implementation of the Required Referral law.
- Strengths: has a comparison group; prospective.
- Weakness: public opinion (pre-event measure) about organ donation is not well-linked to actual increases in the donation rate; lack of an external comparison group makes it difficult to determine whether changes in public opinion can be attributed to the law or to some other factor (e.g., increased media coverage in the state).
B. Provider Education and Organization
Another set of programs focuses on provider education and organization. These programs address hospital and OPO readiness to effectively handle potential donors so as to maximize organ donation. Such programs might include training for hospital and OPO staff, involvement of OPO staff in the hospital infrastructure, and other similar efforts.
Sample hypothesis: Placing OPO coordinators on-site at hospitals will facilitate the organ donation process and increase organ donation rates.
Sample evaluation option:
- Select 50 trauma centers without in-house OPO coordinators and randomly assign 25 to receive an in-house OPO coordinator. Measure the difference in donations per potential donor after 6 months.
- Strengths: prospective; randomized; externally controlled; donation rate measure.
- Weaknesses: expensive to conduct medical records review and to continue study for a 6 month period; sample size is potentially too small to detect statistically significant differences.
C. Public Awareness
Perhaps the programs with the highest profile nationally are those that are geared towards raising public awareness towards organ donation issues. There are 269 million people in the US, only a very small fraction of whom will become potential donors (fewer than 20,000 annually). Consequently, for every potential donor, a public awareness campaign must reach, on average, approximately 13,000 people. Casting such a wide net for a small number of donors complicates evaluation of actual effect on donation. However, there are intermediate measures that can be especially useful in gauging programs’ important side effects, such as public education and awareness. Though these do not correlate directly with donation, they can be considered worthy goals on their own in that they can affect national and regional acceptance and support of organ donation programs.
Sample hypothesis: A statewide media campaign consisting of radio and print ads will increase the organ donation rate in the state.
Sample evaluation options:
- Survey 100 families who chose to donate organs and 100 families who chose not to donate organs to determine if the media campaign had any effect on their decision.
- Strengths: controlled; focused on families closest to actual donation.
- Weaknesses: retrospective; response rate to survey may vary by donors and non-donors, biasing results; donating families may have self-selected for reasons other than media campaign.
- Field a survey that classifies respondents according to the five stages of change, based on Prochaska’s transtheoretical change model (1992), before and at two month intervals after the media campaign is implemented.
- Strengths: prospective; stronger measure of campaign success than general public opinion survey.
- Weaknesses: self-controlled; not proximal to actual donation event (pre-event measure).
V. Conclusions
Designing the best evaluation for a specific organ donation activity can reflect practical considerations as well as principles of scientific rigor. Every organ donation activity can be evaluated with some degree of rigor and every existing evaluation can be improved. The degree to which these studies are evaluated depends largely on the appropriate balance of study strength, available resources and other practical constraints. The guidelines set forth in this paper are not rigid standards. They are by no means exhaustive, but represent strengths and weaknesses of alternative approaches to meet the challenge of evaluating organ donation programs.
Appendix A: Selected Definitions of Evaluation Types
Case-control study: a retrospective observational study in which investigators identify a group of patients with a specified outcome (cases) and a group of patients without the specified outcome (controls). Investigators then compare the histories of the cases and the controls to determine the extent to which each was exposed to the intervention of interest.
Cohort study: an observational study in which outcomes in a group of patients that received an intervention are compared with outcomes in a similar group i.e., the cohort, either contemporary or historical, of patients that did not receive the intervention. In an adjusted- (or matched-) cohort study, investigators identify (or make statistical adjustments to provide) a cohort group that has characteristics (e.g., age, gender, disease severity) that are as similar as possible to the group that experienced the intervention.
Cross-sectional study: a (prospective or retrospective) observational study in which a group is chosen (sometimes as a random sample) from a certain larger population, and the exposures of people in the group to an intervention and outcomes of interest are determined.
Randomized controlled trial (RCT): a true prospective experiment in which investigators randomly assign an eligible sample of patients to one or more treatment groups and a control group and follow patients’ outcomes.
Time-series: a (prospective or retrospective) study in which a group or individual is measured at regular intervals before an after an intervention to determine trends.
Appendix B: An Overview of Selected Evaluations from the Organ Donation Literature
A. Table of Organ Donation Activity Evaluations
| Study | Overview | Evaluation | Performance Indicators | Stage of Activity | Target | Findings | Comments |
|---|---|---|---|---|---|---|---|
| Public Awareness | |||||||
| Cosse 1997 | Media campaign in US by the Advertising Council, Inc. to educate US public about organ and tissue donation (Phase II July 1995, Phase II October 1995). | Time series | Pre-event measures: % who expressed a positive attitude towards organ donation;
% who signed donor card |
Pre-event activity | Community | Campaign found an increased percentage of people taking action to sign a donor card after the campaign. | The activity described is one step removed from actual organ donation, but was successful in terms of raising awareness. However, the media campaign wasn’t isolated, other activities may have also contributed to this change (e.g., reports about famous recipients like Mickey Mantle and David Crosby). |
| Schutt 1997 | A mailing campaign and public lectures were coordinated through a large medical insurance company; other materials were distributed via affiliated hospitals and the local news media. | Time series | Rate of organ donation increased by 30% during first 3 months of 1997 compared with same time previous year. | Pre-event activity | Combined public/ hospital/ primary care provider awareness | The rate of organ donation increased in 1997, although PCPs were reluctant to distribute information to patients. | Multi-faceted approach with a baseline measurement and follow-up based on actual rate of organ donation. No way to tell which facet of the program had largest impact. No attempt to control for other confounding factors that may have influenced the donation rate. |
| Persijn 1997 | Various public education efforts and the professionalization of an information dissemination office. | Time series | Pre-event | Pre-event | Community | Increase in different promotional materials disbursed. | Very easily collected, but more an illustration of a dissemination office increasing its activity intensity- no post-event or outcome measurements. |
| Townsend 1990 | Discussion groups to educate the African-American community about donation. | Time series | Pre-event | Pre-event | Community | Increase in donation approval and family discussion after group meeting. | Questionnaire easy to collect, but difficult to link activity to organ donation. |
| Kappel 1993 | Two phase effort to increase donation from the African-American community: public education and minority requestor. | Time series | Post-event | Pre-event | Community | Increase in black referrals, but consent rate remained the same. | The disconnect between referral and consent was discussed; data simple to collect; small sample size (5/16 and 4/31). |
| Callender 1991 | Various efforts for African-American community education. | Time series | Pre-event
Donation rate |
Pre-event | Community | Increase in donor cards signed at DMV over campaign.
Increase in donations over period of campaign. |
Good measure of approval/ commitment, easy to collect.
Used only # of donations in 80-89; no rates to adjust for population size or technological advances over a decade; not clear what aspect of a multi-faceted program had the most positive effect. |
| Wolf 1997 | National strategy to promote public acceptance of organ donation. | Cross-sectional survey (incomplete) | Pre-event | Pre-event | Community | Media penetration strong; positive response in favor of donation for those viewing campaign. | Survey fairly easy to collect but must be large; no comparison of change in attitudes of those who hadn’t seen campaign for control. |
| Gallup 1993 | Survey on public attitudes about donation. | N/A – survey | Pre-event | N/A | Community | National approval of organ donation, etc. | Baseline only- might be useful to measure difference over time or by region of intervention. |
| Stratta 1997 | Hypothesis that organ donation rate would increase if the public could be assured that donated organs are appropriately used. | N/A | Consent rate,
rate of nonrecovery (including donor instability and inability to find recipient), disease/damaged organs, consent rate, utilization |
Post-donation | Community | N/A | Not a true evaluation but analyzes steps in the process to identify areas for future activity. Recognition that consent is part of the issue, but hospital needs to improve efforts to use a retrieved organ. |
| Provider education and hospital/OPO organization | |||||||
| BNA, Feb. 2, 1998 | Retrospective survey of donor families and critical care staff concerning perceptions of quality of care and training respectively. | Case-control study | Post-event measures, but focus on quality of hospital care. | Post-event | Hospital, donor and nondonor families | Donor families ranked the quality of care their loved one received higher than non-donor families. | Although this study does not evaluate an activity, the information from this study can be used to identify new interventions to improve quality of care and increase donations. |
| Chabalewski 1997 | A program to promote a greater emphasis on organ donation issues in nursing education programs in the US. | Time series | Pre-event measures of how many schools incorporate donation & transplantation activities in their curriculum | Pre-event | Hospital – Nursing schools | Nursing schools have become more aware and have started to incorporate more Donation &Transplantation courses and information in their curriculum. | Study is an indirect proxy of ultimate organ donation Focus on those directly involved in the organ procurement process post-event, but indirect. Study possibly could be followed up to link education to attitudes and success in clinical practice. |
| Garrison 1991 | Analysis of Kentucky OPO performance over one year. | Cohort | Post-event | Post-event | Donors/ families | Consent rate higher in cohort for whom requests were decoupled from brain death explanation. | Nondeliberate, but good design: presumably randomization of decoupled request though small number of hospitals suggests issues about one or two poor requestors who might have skewed results. |
| Hartwig 1993 | Effect of organ donor race on health team procurement efforts. | Cohort | Post-event | Post-event | Hospital | African-American patients are less likely to be identified, asked, or become donors. | Sample size decent- 85 and 67; use of MRR mitigated potential for skewed results from staff knowing there is interest in studying this issue; MRR involves time and effort. |
| Niles 1996 | Evaluation of the timing factor in the consent process. | Cohort | Post-event | Post-event | Donor/ families | Decoupled requests more successful. | Retrospective study; relatively easy to collect data; OPO-wide sample large enough to be significant. |
| Cutler 1992 | An analysis of donation events in one OPO over two years. | Cohort | Post-event | Post-event | Donor/ families | OPO coordinators more effective at soliciting consent than physicians. | Study doesn’t give numbers of cases, only rates, and says physicians ask most often- if much more often, coordinator success might be less on account of coordinator status than particular success of one good coordinator. |
| Sheehy 1996 | Comparison of procurement success between trauma and non-trauma hospitals. | Cohort | Donation rate, post-event | (No activity) | Hospital | Trauma centers are more effective at each of the post-event steps and in donation rate. | Baseline data only; MRR used is relatively expensive. |
| Beyer 1992 | Study of donations at a Midwest tertiary care hospital over six months. | Cohort | Post-event | Post-event | Donor/ families | Physician request consent rate higher than when nurse requests; consent rate also higher with higher Death Anxiety Scale (DAS) scores and more liberal religious beliefs (1-6 scale). | Regressions performed to calculate results; sample size of 228 requests might be too small to break out so many variables with significance; prospective design stronger than most. |
| Beasley 1997 | Impact of a comprehensive, hospital-focused intervention to increase organ donation over two years at 50 hospitals in three OPOs. | Time series | Post-event, donation rate | Post-event | Hospital (from OPO) | All measures from ID to donations increased pre-intervention to post-intervention. | Large sample lends credibility, as does pre- and post-intervention, rather than during, when there might be a learning curve; data collection largely a part of intervention except MRR, which is relatively onerous. |
| Cohort | Post-event | Post-event | Hospital (from OPO) | Consent rate higher among cohorts for which request was decoupled, made in a quiet/private setting, and OPO coordinator involved. | Again, large sample lends credibility, though results might be skewed in that procurement staff might not have followed guidelines for decoupling, etc., even in the midst of an intervention. | ||
| Shafer 1997 | Impact of inhouse coordinators on organ donation rates in non-donor hospitals, a single coordinator has a contractual obligation to identify and manage potential donors. | Time series | Donation rate
Post-event measures: Organ donor referrals, donor count, consent rate |
Post-event | Hospital level, but sponsored by the OPO | The program has been a cost-effective way of assisting OPO’s efforts to recover organs from hospitals in Texas. | Actual evaluation with outcomes measures, 3-year follow-up. Working directly in the hospital post-event to improve family consent rates, routine notification, and communications with the OPO. |
| Gentry 1997 | Using an "appropriate messenger" (Dr. Callender) approach by hiring an African-American to spearhead a minority community education program and having an on-call African-American coordinator to increase donation rates. | Time series | Organ donation
Post-Event: Consent Rates Referral rate Medically suitable donor referrals |
Post-event | OPO program initiated at the hospital level | Consent rates and donation rates increased among African-American donors. | Targeted population in North Texas, focus on increasing minority consent Study design does not control for other potential confounding factors that could have impacted the donation rate beyond the OPO-coordinator program. |
| Shirley 1994 | Assessment of one OPO’s efforts to increase donation by a variety of initiatives. | Time series | Donation rate, post-event | Pre-event, Post-event | Hospital (from OPO) | Doubling of referrals and donations since beginning of program. | Large enough results that program probably works, but the role of each part of a multi-faceted campaign unclear; data easy to collect. |
| Politoski 1994 | Description of continuing education program offered by the National Kidney Foundation. | Time series | Post-event | Pre-event | Hospital | After the workshop, nurses are more likely to identify donors, initiate requests, and accompany requestor. | Relatively easy to collect; translation of pre-event intervention to post-event behavior particularly good (though link to success of these requests would be instructive)- contemporaneous controls might have been useful. |
| Burris 1996 | Effect of a program to define a donation policy, educate staff, and document and monitor compliance at one institution. | Time series | Donation rate, Post-event | Post-event | Hospital, Donors/ families | After implementation of CQI, significant increases in referrals and donations. | Good to measure both donation rate and post-event indicators: sample size for donation rate larger (so more confidence in results), but post-event measures are also significant. Use of request protocol form facilitated data collection. |
| Kappel 1993 | Two phase effort in increase donation from black community: public education and minority requestor. | Time series | Post-event | Post-event | Donors/ families | Increase in consent rate over time. | Good to use post-event measure, but sample size might be too small- researcher doesn’t explain why referrals actually went down over the year of intervention. |
| GAO 1993 | Survey of OPOs on their data collection variables. | N/A --Survey | Post-event | Pre-event | OPO | What variables OPOs collect, and to what extent. | Point: OPOs should collect more, and more consistent, data. |
| Savaria 1990 | Feedback solicited from families of donors. | N/A --Survey | Pre-event, Post-event | Post-event | Donor/ families, Community | Questions asked about whether donor had donor card or family discussion before precipitating event; also reasons for donating. | No comparison with control group of non-donor families; 50% response rate compromises results; sensitive issue; relatively inexpensive. |
| Shafer 1997 | Study of organization of three successful organ procurement organizations. | N/A --Survey | Outcomes, Post-event, Pre-event, other | Both | OPO | No conclusions drawn, just benchmarks suggested for successful OPOs. | Might have relevance with much larger sample sizes that include true cross-section of OPOs (not just three successful ones) to see which variables really do correlate with success. |
| Morris 1990 | Performance of one hospital over 3 years. | Single case | Post-event | Post-event | Hospital | Baseline data established. | Sample size of 10 over 3 years compromises results; MRR to determine potential donors might have been costly. |
| Kowalski 1996 | Assessment of a hospital’s establishment of an Office of Decedent Affairs, whose staff facilitate various aspects of the donation process. | Single case | Outcome | Post-event | Hospital | After office consolidation, donation rate tripled. | Outcome measure suggests success, but unclear which aspect of a multifaceted effort is responsible; easily measured. |
| McNamara 1997 | Medical record review to determine organ procurement effectiveness. | Methods | Donation rate, Post-event | Post-event | OPO, Hospital | MRR is stronger than death certificate review which is stronger than DPMP as performance measures. | Good methodological recommendations. |
| Evans 1992 | Death certificate review to determine organ procurement effectiveness. | Methods | Donation rate | Post-event | OPO, Hospital | Gives two death certificate review methods to determine potential donor pool. | Methodological recommendation; baseline data only. |
| Wight 1997 | Describes the European Donor Hospital Education Programme skills workshop and Donor Action, a program designed to help hospitals improve policies and procedures to optimize donation process with 5 modules: donor detection, referral, family care and communication, maintenance, retrieval. | N/A | Pre-event measures: Increasing attitude, knowledge, communication, teamwork;
Post-event: increasing approaches to families Donation rates via MRR |
Pre-event activity to help hospitals better handle events | Hospital | N/A | Donor Action program has targeted key weaknesses and identified areas where the most donors were being "lost" -- changes could be measured on a hospital by hospital basis -- this article does not describe any evaluation. MRR and hospital staff surveys are generally expensive to conduct. |
| Matesanz 1997 | Proposal of future activities: proactive donor detection programs with specifically trained professionals, education of the legal profession, social education of health professionals, media, and public opinion, and organizational structure of the organ donation system are all crucial. | N/A | Ultimately would have to include all three performance indicators | Pre-event | Range of activities targeting all stakeholders | N/A | Proposes a wide range of activities but no planned evaluation beyond national organ donation rates and country vs. country comparisons. |
| Legislation | |||||||
| Roels 1996 | Evaluates presumed consent policies in Austria and Belgium. | Cohort | Donation rates | Pre-event | Community | DPMP higher in countries with presumed consent policies. | Without mention of baseline, not clear that differences don’t correlate with societal differences, but use of two countries eases this issue somewhat- perhaps baseline data could have been included as a historical control; easy to measure. |
| Bergstrom 1997 | Swedish Transplant Coordinators’ experience with the New Transplantation Act and Donor Register which switched presumed non-consent to presumed consent – Government led information campaign, national database of donors and an attitude survey. | Time series | # of donors, survey of pre-event measures (e.g., donor card signing), and post-event measures (consent rates) | Pre-event | Community | No difference in number of donors in Sweden had been detected. | This study provides one example of how difficult it is to measure changes in the donation rate due to legislation and public awareness activities. The time span of the study may have been too short to detect differences. |
| Bacque 1997 | Development of laws (in Argentina) to ensure transparency and sanitary safety in the development of organ transplantation – Organ Transplant Law 1977 created the National Organ Procurement Organism, shift towards improving provider attitudes and creating a new operational model – Hospital Coordinator Model, and educational campaigns. | Retrospective time series | DPMP, post-event, and pre-event measures.
Percentage of multiorganic retrieval, Family refusal rates, Percent lack of information about brain death and corpse integrity, Religious refusal, Percent mistrust |
Pre-event | Community, hospital providers | Found an increase in donation rates and numbers of organs retrieved since legal organization of the organ donation system; Outlines goals for new model as Argentina moves forward. | Measures organ donation outcome on a county by county level, measures intermediary predisposition to organ donation. Accounts for effect of government and transplantation model. Age of donors has remained relatively constant. |
| Nitschke 1997 | Comparing legislative periods in Germany with transplantation law and without law but with a centralized system of organ procurement; describes role of the Eurotransplant Foundation to standardize allocation procedures. | Time series | # of potential organ donors and outcome: effective donors and organs retrieved; refusal rate influenced by the media | Pre-event | Community | The new allocation procedures seem to be successful, despite moving to a system that requires next-of-kin consent. | This study measures real outcomes and controls for the death rate but does not control for the fact that the increase in organs may be due to differences in the donor identification rate or other population differences. |
| Transplant News 1996 | Illinois donor card registry. | Surveillance | Pre-event | Pre-event | Community | % of drivers registered as donors by region used to determine where awareness is lacking. | Good use of registry data to focus later program initiatives; could eventually link this data to actual donation rates. |
| Roels 1997 | Presumed consent policy in Belgium. | Surveillance | Pre-event | Pre-event | Community | Rate of opt-outs determined for natives and foreigners. | Baseline only; could use this data to determine change over time, and compare with other countries. |
| Overcast 1984 | Survey of OPOs and state District Attorney offices. | N/A --Survey | Pre-event (donation rate connection hinted at anecdotally) | Pre-event, Post-event | Community | Most states allow donor designations on licenses; anecdotal information given on % of actual donors who had been donor card carriers; most states don’t have official protocol for police to search for a donor card on an accident scene. | Potential to use registries to link actual donors with donor card carriers mentioned, but only anecdotally mentioned. |
| Rosental 1997 | Comparison of informed versus presumed consent law in Baltic States - creation of unified Baltic transplant network. | N/A | Donations per million population, development of joint policy, adopting legislation, unified waiting list | Pre-event | Community | Rates of transplantation were similar in the Baltic states; the states are now unified by the Balttransplant organization. | Not a true evaluation, could be evaluated if comparisons are made at baseline (pre-organization) and at intervals after baseline. |
B. Organ Donation References
Alleman K, Coolican M, et al. Public perceptions of an appropriate donor card/brochure. J Transpl Coord. 1996; 6: 105-108.
Arnold RM, Siminoff LA, Frader JE. Ethical issues in organ procurement: A review for intensivists. Med Ethics. 1996; 12(1): 29-48.
Bacque MC, Cambariere R. The organ shortage: what are organ sharing organizations doing about it? Transplant Proc. 1997; 29(8): 3211-4.
Barnett AH, Kaserman DL. The shortage of organs for transplantation: Exploring the alternatives. Issues in Law & Med. 1993; 9(2): 117-137.
Beasley CL, Capossela CL, et al. The impact of a comprehensive, hospital-focused intervention to increase organ donation. J Transpl Coord. 1997; 7(1): 6-13.
Bergstrom C, Svensson L, et al. The Swedish Transplant Coordinators' experience of the new Transplantation Act and the donor register 1 year after implementation. Transplant Proc. 1997; 29(8): 3232-3.
Beyer MC, Zanetos MS. Factors influencing response to organ/tissue donation requests: implications for educational programs. Dialysis and Transplant. 1992; 21(12): 794-805.
Brewer JC, Hunt MJ, Seely MS. Routine inquiry of organ and tissue donation: The Oregon experience. Crit Care Nurs. 1994; 6(3): 567-574.
Burris GW, Jacobs AJ. A Continuous quality improvement process to increase organ and tissue donation. J Transpl Coord. 1996; 6(2): 88-92.
Callender CO, Hall LE, et al. Organ donation and blacks: A critical frontier. New Eng J Med. 1991; 325(6): 442-444.
Chabalewski FL. A success story: promoting the incorporation of donation - and transplantation-related content in nursing school curricula. Transplant Proc. 1997; 29(8): 3240-1.
Cohen B, D’Amaro J, et al. Changing patterns in organ donation in Eurotransplant, 1990-1994. Transpl Int. 1997; 10(1): 1-6.
Cohen B, Persijn GG. Trends in organ donation. Transplant Proc. 1997; 29(8): 3301-2.
Corlett S. Public attitudes toward human organ donation. Transpl Proc. 1985; 17(6, Suppl 3): 103-110.
Cosse TJ, Weisenberger TM, Taylor GJ. Walking the walk: behavior shifts to match attitude toward organ donation. Transplant Proc. 1997; 29(8): 3248.
Council on Ethical and Judicial Affairs, American Medical Association. Strategies for cadaveric organ procurement: Mandated choice and presumed consent. JAMA 1994; 272(10): 809-812.
Council on Ethical and Judicial Affairs, American Medical Association. Financial incentives for organ procurement: Ethical aspects of future contracts for cadaveric donors. Arch Intern Med. 1995; 155: 581-589.
Cutler JA, David SD, et al. Increasing the availability of cadaveric organs for transplantation: maximizing the consent rate. Transplantation. 1993; 56(1): 225-228.
Davidson I, Exley M, et al. Increasing organ donation at a large inner city public hospital. Transpl Proc. 1993; 25(6): 3139.
DeJong W, Drachman J, et al. Options for increasing organ donation: The potential role of financial incentives, standardized hospital procedures, and public education to promote family discussion. Milbank Quarterly. 1995; 73(3): 463-479.
Devney P. Organ donation and African Americans. J Transpl Coord. 1991; 1: 2-4.
Dunn D. Motivations for giving: Consent for the donation of organs and tissues. J Transpl Coord. 1995; 5: 2-8.
Durand-Zaleski I, Waissman R, et al. Nonprocurement of transplantable organs in a tertiary care hospital: A focus on sociological causes. Transpl. 1996; 62(9): 1224-1229.
Evans RW, Manninen DL. US public opinion concerning the procurement and distribution of donor organs. Transpl Proc. 1988; 20(5): 781-785.
Evans RW, Orians CE, Ascher NL. The potential supply of organ donors: An assessment of the efficiency of organ procurement efforts in the United States. JAMA. 1992; 267(2): 239-246.
Evans RW. Incentives for organ donation. Lancet. 1992; 339: 185.
Evans RW. Organ procurement expenditures and the role of financial incentives. JAMA. 1993; 269(24): 3113-3118.
First MR. The donor supply. Transplant Proc. 1997; 29(8): 3299-3300.
Franz HG, DeJong W, et al. Explaining brain death: a critical feature of the donation process. J Transpl Coord. 1997; 7: 14-21.
Franz HG, Drachman J, et al. Public attitudes toward organ donation: Implications for OPO coordinators. J Transpl Coord. 1995; 5: 50-54.
Gabel H, Renqvist N. Information on new transplant legislation: how it was received by the general public and the action that ensued. Transplant Proc. 1997; 29(7): 3093.
Gaber AO, Hall G, Britt LG. An assessment of the impact of required request legislation on the availability of cadaveric organs for transplantation. Transpl Proc. 1990; 22(2): 318-319.
Gallagher H, Smolinski SE, et al. In-house transplant coordinator increases referrals and donations. J Transpl Coord. 1992; 2: 136-139.
Gallup Organization, Inc., The. The American Public’s Attitudes Toward Organ Donation and Transplantation. Conducted for The Partnership for Organ Donation, Boston, MA. Feb 1993.
Ganikos ML, McNeil C, et al. A case study in planning for public health education: The organ and tissue donation experience. Public Health Reports. 1994; 109(5): 626-631.
Garcia VD. Financial and legislative issues. Transplant Proc. 1997; 29(8): 3256-7.
Garrison RN, Bentley FR, et al. There is an answer to the shortage on organ donors. Surg Gyn Ob. 1991; 173: 391-396.
General Accounting Office. Organ Transplants: Increased Effort Needed to Boost Supply and Ensure Equitable Distribution of Organs. GAO/HRD-93-56, 1993.
Gentry D, Brown-Holbert J, Andrews C. Racial Impact: increasing minority consent rate by altering the racial mix of an organ procurement organization. Transplant Proc. 1997; 29(8): 3758-9.
Gibson V. The factors influencing organ donation: A review of the research. J Adv Nurs. 1996; 23: 353-356.
Gortmaker SL, Beasley CL, et al. Organ donor potential and performance: Size and nature of the organ donor shortfall. Crit Care Med. 1996; 24(3): 432-439.
Gravel MT, Szeman P. Increasing referrals and donations using the Transplant Center Development Model. 1996; 6(1): 32-36.
Gubernatis G, Vogelsang F, Basse H, Smit H. Relevance of small hospitals for increasing donation rates. Transplant Proc. 1997; 29(7): 3091-2.
Gubernatis G. Solidarity model as nonmonetary incentive could increase organ donation and justice in organ allocation at the same time. Transplant Proc. 1997; 29(8): 3264-6.
Hartwig MS, Hall G, et al. Effect of organ donor race on health team procurement efforts. Arch Surg. 1993; 128: 1331-1335.
Hauptman PJ, O’Connor KJ. Procurement and allocation of solid organs for transplantation. New Eng J Med. 1997; 336(6): 422-431.
Joun Y, Coonan PR, LeGrande ME. Attitudes of Korean-Americans in and around NYC. Transplant Proc. 1997; 29(8): 3751-2.
Kappel DF, Whitlock ME, et al. Increasing African American organ donation: The St. Louis experience. Transpl Proc. 1993; 25(4): 2489-2490.
Kiberd MC, Kiberd BA. Nursing attitudes towards organ donation, procurement, and transplantation. Heart & Lung. 1992; 21(2): 106-111.
Kittur DS, Hogan MM, et al. Incentives for organ donation? Lancet. 1991; 338: 1441-1443.
Klassen AC, Klassen DK. Who are the donors in organ donation? The family’s perspective in mandated choice. Ann Int Med. 1996; 125: 70-73.
Kowalski AE, Light JA, et al. A new approach for increasing the organ supply. Clin Transpl. 1996; 10: 653-657.
Manninen DL, Evans RW. Public attitudes and behavior regarding organ donation. JAMA. 1985; 253(21): 3111-3115.
Marwick C. Key to organ donation may be cultural awareness. JAMA. 1991; 265(2): 176-181.
Matesanz R. The Council of Europe and organ transplantation. Transplant Proc. 1997; 29(8): 3205-7.
McNamara P, Franz HG, et al. Medical record review as a measure of the effectiveness of organ procurement practices in a hospital. J Quality Improvement. 1997; 23(6): 321-333.
Merz B. The organ procurement problem: many causes, no easy solutions. JAMA. 1985; 254(23): 3285-3288.
Morris JA, Wilcox TR, et al. Organ donation: A university hospital experience. South Med J. 1990; 83(8): 884-888.
Morrissey PE, Monaco AP. A comprehensive approach to organ donation. Hosp Pract. 1997; August 15: 181-196.
Niles PA, Mattice BJ. The timing factor in the consent process. J Transpl Coord. 1996; 6(2): 84-87.
Nitschke FP, Feyerherd F, Seiter H, Hudemann B. Why does Mecklenburg-Vorpommern have the highest number of organs available for transplantation within the Eurotransplant Community? Transplant Proc. 1997; 29(8): 3237-9.
Norris MKG. Nurses’ perceptions of donor families’ opinions: Implications for professional educational strategies. J Transpl Coord. 1991; 1: 42-46.
Noury D, Jacob F, et al. Information on relatives of organ and tissue donors. A multicenter regional study: Factors for consent or refusal. Transpl Proc. 1996; 28(1): 135-136.
Overcast TD, Evans RW, et al. Problems in the identification of potential organ donors: Misconceptions and fallacies associated with donor cards. JAMA. 1984; 251(12): 1559-1562.
Page S. Responses of perioperative nurses to organ procurement surgery. Can Oper Room Nurs J. 1996; 14(4): 9-11.
Panico M, Solomon, M, Burrows L. Issues of informed consent and access to extended donor pool kidneys. Transplant Proc. 1997; 29(8): 3667-8.
Pelletier M. The organ donor family members’ perception of stressful situations during the organ donation experience. J Adv Nurs. 1992; 17: 90-97.
Perez LM, Schulman B, et al. Organ donation in three major American cities with large Latino and black populations. Transpl. 1988; 46(4): 553-557.
Perez MS, Trevino L, Swasey L. Hispanic experience of organ donation in New York City. Transpl Proc. 1993; 25(4): 2492-2493.
Perkins KA. The shortage of cadaver donor organs for transplantation: Can psychology help? American Psychologist. 1984; 42(10): 921-930.
Persijn GG, van Netten AR. Public education and organ donation. Transpl Proc. 1997; 29: 1615-1617.
Peters TG, Kittur DS, et al. Organ donors and nondonors: An American dilemma. Arch Intern Med. 1996; 156: 2419-2424.
Peters TG. Financial and legislative issues: selected topics. Transplant Proc. 1997; 29(8): 3254-5.
Plessen V, Kolditz M, et al. Total quality management including a detailed documentation system increases organ donation rates by transparency of information and consecutive motivation. Transpl Proc. 1997; 29: 1496-1497.
Politoski G, Boller J. Making the critical difference: An innovative approach to educating nurses about organ and tissue donation. Crit Care Nurs. 1994; 6(3): 581-585.
Prottas J, Batten HL. Health professionals and hospital administrators in organ procurement: Attitudes, reservations, and their resolutions. AJPH. 1988; 78(6): 642-645.
Prottas J. Shifting responsibilities in organ procurement: A plan for routine referral. JAMA. 1988; 260(6): 832-833.
Prottas JM. Encouraging altruism: Public attitudes and the marketing of organ donation. Milbank Memorial Fund Quarterly. 1983; 61(2): 278-306.
Prottas JM. The structure and effectiveness of the U.S. organ procurement system. Inquiry. 1985; 22: 365-376.
Randall T, Marwick C. Physicians’ attitudes and approaches are pivotal in procuring organs for transplantation. JAMA. 1991; 265(10): 1227-1228.
Rodeheffer RJ, Naftel DC, et al. Secular trends in cardiac transplant recipients and donor management in the United States, 1990 to1994: A multi-institutional study. Cardiac Transplant Research Database Group. Circulation 1996; 94(11): 2883-2889.
Roels L, De Meester J. The relative impact of presumed-consent legislation on thoracic organ donation in the Eurotransplant area. J Transpl Coord. 1997; 6(4): 174-177.
Roels L, Deschoolmeester G, Vanrenterghem Y. A profile of people objecting to organ donation in a country with a presumed consent law: Data from the Belgian National Registry. Transpl Proc. 1997; 29: 1473-1475.
Rosental R, Dainis B, Dmitriev P. BaltTransplant: a new organization for transplantation in the Baltic States. Transplant Proc. 1997; 29(8): 3218-9.
Rudy LA, Leshman D, et al. Obtaining consent for organ donation: The role of the healthcare profession. J South Carolina Med Assoc. 1991; June: 307-310.
Savaria D, Coolican M, Swanson M. The role of focus groups in determining the effectiveness of donor cards. J Transpl Coord. 1992; 2: 122-126.
Savaria DT, Rovelli MA, Schweizer RT. Donor family surveys provide useful information for organ procurement. Transpl Proc. 1990; 22(2): 316-317.
Schütt GR, Smit H, Duncker G. Huge discrepancy between declared support of organ donation and actual rate of consent for organ retrieval. Transpl Proc. 1995; 27: 1450-1451.
Schütt GR; Henne-Bruns D. Organ donation: the influence of personal attitude on professional behavior. Transplant Proc. 1997; 29(8): 3246.
Schutte L, Kappel D. Barriers to donation in minority, low-income, and rural populations. Transplant Proc. 1997; 29(8): 3746-7.
Shafer, Hueneke M, et al. The Texas Nondonor Hospital Project: a preliminary report on the impact of in-house coordinators on organ donation rates in nondonor hospitals. Transplant Proc. 1997; 29(8): 3261-2.
Shafer TJ, Kappel DF, Heinrichs DF. Strategies for success among OPOs: A study of three organ procurement organizations. J Transpl Coord. 1997; 7(1): 22-31.
Sheehy E, Poretsky A, et al. Relationship of hospital characteristics to organ donation performance. Transpl Proc. 1996; 28(1): 139-141.
Shirley S, Cutler J, et al. Narrowing the organ donation gap: Hospital development methods that maximize hospital donation potential. J Heart Lung Transpl. 1994; 13(5): 817-823.
Siminoff LA, Arnold RM, Caplan AL. Health care professional attitudes toward donation: Effect on practice and procurement. 1995; 39(3): 553-559.
Siminoff LA, Arnold RM, et al. Public policy governing organ and tissue procurement in the United States: Results from the National Organ and Tissue Procurement Study. Ann Intern Med. 1995; 123: 10-17.
Sirchia G, Mascaretti L. Family consent: Legal and cultural background. Transpl Proc. 1997; 29: 1622-1624.
Sloan FA. Organ procurement: Expenditures and financial incentives. JAMA. 1993; 269(24): 3155-3156.
Spital A. Mandated choice for organ donation: Time to give it a try. Ann Int Med. 1996; 125(1): 66-69.
Spital A. Mandated choice: A plan to increase public commitment to organ donation. JAMA. 1995; 273(6): 504-506.
Spital A. Testing remedies for the shortage of organs. Ann Int Med. 1992; 116(5): 428-429.
Spital A. The shortage of organs for transplantation: Where do we go from here? New Eng J Med. 1991; 325(17): 1243-1246.
Stratta RJ, Bennett L. Pancreas underutilization in the US: analysis of United Network for Organ Sharing data. Transplant Proc. 1997; 29(8): 3309-10.
Stuart FP, Veith FJ, Cranford RE. Brain death laws and patterns of consent to remove organs for transplantation from cadavers in the United States and 28 other countries. Transpl. 1981; 31(4): 238-244.
Townsend ME, Rovelli MA, Schweizer RT. Value of discussion groups in educating blacks about organ donation and transplantation. Transpl Proc. 1990; 22(2): 324-325.
Transplant News Staff. Illinois Secretary of State Ryan setting standard for developing state program in increase donation. Transpl News. May 28, 1996.
Tymstra T, Heyink JW, et al. Experience of bereaved relatives who granted or refused permission for organ donation. Family Practice. 1992; 9(2): 141-144.
Van Da Walker SG. The attitudes of operating room nurses about organ donation. J Transpl Coord. 1994; 4: 75-78.
Veatch RM, Pitt PB. The myth of presumed consent: Ethical problems in new organ procurement strategies. Transpl Proc. 1995; 27(2): 1888-1892.
Veatch RM. Routing inquiry about organ donation- An alternative to presumed consent. New Eng J Med. 1991; 325(17): 1246-1249.
Veatch RM. Non-heart-beating cadaver organ procurement: two remaining issues. Transplant Proc. 1997; 29(8): 3339-40.
Verble M, Worth J. The case against more public education to promote organ donation. J Transpl Coord. 1996; 6: 200-203.
Virnig BA, Caplan AL. Required request: What difference has it made? Transpl Proc. 1992; 24(5): 2155-2158.
Vrtis M, Nicely B. Nursing knowledge and attitudes toward organ donation. J Transpl Coord. 1993; 3: 70-79.
Wight C, Cohen B. What is the Eurotransplant Foundation doing about the organ shortage. Transplant Proc. 1997; 29(8): 3208.
Wolf JS, Servino EM, Nathan HN. National strategy to develop public acceptance of organ and tissue donation. Transpl Proc. 1997; 29: 1477-1478.
Appendix C: An Overview Of Selected Studies from the Health Behavior Change Evaluation Literature
A. Table of Health Behavior Activity Evaluations
| Study | Overview | Evaluation | Performance Indicators | Target | Findings | Comments |
|---|---|---|---|---|---|---|
| Smoking Cessation | ||||||
| Lando 1991 | General media campaign tied to a contest to ensure follow-up; Evaluated using telephone surveys to compare those who sent in interest cards and pledged to stop-smoking versus those who sent in cards but did not pledge to stop smoking | Nonrandomized trial with contemporane-ous controls, also compared outcomes from previous study (historical control) | Outcomes – comparing difference in quit rates between pledgers and non-pledgers | Community- wide intervention, public awareness activity | Study contained two comparisons: (1) historical control and (2) differences between pledgers. The study found that an extended enrollment period and intensive campaign increased enrollment, and overall quit rates. Pledgers had higher self-reported abstinence rates. | No control group of a community without the intervention, but the historical control is a good indicator of change; detects differences in those who quit versus those who did not |
| Popham 1993 | A group of people who quit smoking were selected from the entire population of those exposed to California’s anti-tobacco media campaign to measure the exposure of those who quit to the campaign | Cross-sectional study, retrospective, no comparison group | Whether or not respondents saw the advertisements;
Attempt to determine if process correlates to the specified outcome |
Community, public awareness activity | Study sought to evaluate what influenced people to stop smoking during the campaign and determined that the media campaign had influenced change | No comparison group for this study; other smokers who didn’t quit smoking may have seen the study and not quit |
| Werch 1994 | Applies Prochaska’s stages of change model to the formation of a unhealthy behavior to better focus prevention strategies; Paper is theoretical without an actual intervention | Methods/theory paper | N/A | Community, Public Awareness | N/A | Applies health belief, social learning, and behavioral self-control theories to stages of change and strategies that could be used in prevention or behavior promotion; May provide a good theoretical background |
| Prochaska 1983 | Used a test of 40 questions to track subjects for 2 years to determine the progression through stages of change related to quitting smoking | Methods/theory paper | N/A | Community, Public Awareness | N/A | No evaluation of specific intervention but may be correlated to success in stages of change |
| Prochaska 1992 | Outlines process by which addictive behaviors are modified and stages of change: precontemplation, contemplation, preparation, action and maintenance | Methods/theory paper | N/A | Community, public awareness | N/A | Stages of change may be a useful aid to evaluate organ donation strategies; a baseline study could determine how people cycle through the stages of change leading to consent; then, interventions could be designed and evaluated based on these stages of change |
| Mammography and Other Cancer Screening | ||||||
| Strickland 1997 | Compared the impact of three interventions (physician message, message with class, message, class and reinforcement) on breast self examination compliance | Large randomized controlled trial | Percentages of women doing breast self exams at 2 follow-ups over the course of 1 year | Provider organization intervention, women general awareness | The more comprehensive intervention was more successful in the number of women doing breast self examination | One of the few examples of a large RCT done to influence health behavior changes that may serve as a good model for the organ donation world (particularly because of the provider education/support focus) |
| Champion 1995 | An evaluation to measure the effect of an individualized belief and/or information intervention on mammography compliance | Randomized controlled trial | Stages of change and adherence to mammography screening | Control group and 3 intervention groups; educational activity | Women in the belief/ information group were 2x more likely to have been compliant with intervention 1 year later; women receiving the belief intervention were more likely to move to a higher stage of change | A good example of a randomized, controlled trial used in program evaluation regarding health behavior education with 4 randomized intervention groups, baseline screening and 2 follow-up measurements |
| Campbell 1997 | An office-based computer system was randomized to provide women who filled out a computer health survey with either follow-up recommendations or no recommendations. Study sought to determine if these recommendations made a difference | Small randomized controlled trial | Compared #s who had a PAP smear in the 6 months following the visit | Targeted members of community, public awareness | Results were inconclusive | The investigators were unable to draw conclusions regarding the effectiveness of the computer system due to the modest proportions of women screened, the small numbers, and the fact that the computer survey may have created an intervention effect in the control group |
| Worden 1994 | Description of a study design methodology based on baseline data to assess women’s participation in mammography, clinical breast examination, and breast self-examination and to measure factors that may affect their participation. | Nonrandomized trial with contemporaneous controls | Will look at intermediate objectives, behavioral outcomes, and health benefits | Women, their physicians, and the health care system in a single, comprehensive program; public awareness activity and provider education and support | The telephone survey did not receive as good a response as the household surveys | Sets up a useful framework for designing an evaluation of a multi-level intervention; uses baseline survey data to develop program components |
| Rakowski 1992 | Survey to assess whether or not stages of change impacted women’s decision about mammography | Survey, one point in time | Questions developed to assess stages of change and at what stage certain behaviors were adopted | Community, public awareness | Provided results that could be used to extend the transtheoretical model of behavior change to mammography screening | Provides a model for the kind of baseline study that the organ donation community could use to learn how to measure stages of change. Then actions could be planned from this study. |
| Rakowski 1997 | Survey to examine the utility of the construct of decisional balance for mammography and pap testing | Survey | Attitudes regarding testing and recent testing behavior | Community, public awareness activity | Options about testing may carry over for several kinds of testing. | The ability to employ combined indicators for frequency of testing and test-related opinions is promising for being able to take a more comprehensive approach to women’s health. |
| Mayer-Oakes 1996 | Longitudinal study of women under the care of internists to determine factors that predict mammography use | Telephone survey | Sociodemograph-ics, physical functioning, psychosocial functioning, preventive and self-care behaviors and mammography use | N/A – no intervention but a survey of women in general | Mammography screening was significantly higher among women who had recently received a Pap smear, whose annual household incomes exceeded $30,000 and whose personal health care habits were preventively oriented. | A baseline survey from which interventions could be built and evaluated |
| Savage 1996 | Survey to assess the Health Belief Model in relation to a Woman’s decisions to have screening mammographies and do breast self examinations | Telephone survey | Questions developed to assess correlates of health behaviors including demographics and attitudes | N/A – no intervention but a survey of women in general | Different variables were found to be predictors of adherence to mammography and breast self exam | A baseline survey from which interventions could be built |
| Scammon 1995 | An evaluation of the role of free mammograms in motivating first-time screening in a community. | Series of consecutive cases | Demographics and attitudes of factors in decision to get mammogram were measured. | Women, asymptomatic for breast cancer, 35 and older; public awareness activity | The free mammography may have helped bring women in, but other factors need to be reinforced (i.e., the feeling of doing something good) to maintain screening patterns. | No controls, and women who were willing to return the survey are the results that were included. |
| Physical Activity Promotion / Obesity Treatment | ||||||
| Stone 1996 | An 8-year multicenter randomized trial investigating whether behaviorally oriented cardiovascular school and family-based health program produced positive changes in the health habits that favorably affect the cardiovascular risk profile of elementary school preadolescents. | Large randomized controlled trial (unit of randomization is the school rather than individuals) | Outcome measures including changes in serum cholesterol, physical activity, and dietary measures | Individual students and family, public awareness activity | As of publication, data analysis was in progress. However, due to low prevalence rates of smoking in the 5th grade, the study did not have sufficient power to detect differences between experimental and control groups. | This trial uses schools as the unit of randomization – similarly the organ donation community could use hospitals or regional-OPOs as the level of randomization. |
| Marcus 1997 | A pilot study to test the feasibility and efficacy of a physician-delivered physical activity counseling intervention. | Small randomized controlled trial | Physical activity levels | Provider education to improve patient results | Physician-delivered physical activity interventions may be an effective way to achieve wide-spread improvements in the physical activity of middle-aged and older adults. | This small scale study may be similar to the kinds of hospital-level provider education efforts conducted in the organ donation community. |
| Cakfas 1997 | Evaluated whether an intervention to change physical activity changed such mediators as stages of change, self-efficacy and social support, and whether changes in the mediators were associated with behavior change. | Nonrandom contemporaneous control | Mediators (changes in stages of behavior) and outcomes (actual changes in behavior) | Providers and patient education program | Patients who were counseled improved significantly more than those in the control group on behavioral and cognitive processes of change. Two of three mediator variables were associated with changes in physical activity. | Serves as a good model for how the organ donation community might test stages of change model, however measuring donations as a result of this intervention might be difficult. |
| Fontaine 1997 | Tested a self-efficacy questionnaire to assess its predictive validity in treatment outcomes for obesity | Time-series | Outcome measures of attendance and weight loss, intermediate measures of self-efficacy | Individual patients, awareness | Self-efficacy judgments (as measured by the Weight Efficacy Lifestyle Questionnaire) are not predictive of short-term obesity treatment outcomes | Another example of a study used to test the predictive value of measures of propensity to change health behaviors |
| Marcus 1992 | Survey to assess whether or not stages of change and self-efficacy impact exercise behavior change | Survey, one point in time | Questions developed to assess stages of change and at what stage certain behaviors were adopted | Community, public awareness activity | Provided results that could be used to extend the transtheoretical model of behavior change to stages of exercise behavior change; basic goal is to develop a reliable instrument | Provides a model for the kind of baseline study that the organ donation community could use to learn how to measure stages of change; actions could be planned from this study |
| Potvin 1997 | Documented the differing prevalence rates for stages of change for physical activity across rural, suburban and inner city communities using survey methods and controlling for education, gender and disease status | Survey | Stage-of-change measurements | Community, public awareness | The findings suggest that above and beyond individual difference variables, structural components such as type of community are related to people’s readiness for physical activity involvement | There may be community-level or other types of factors which influence the stage of change someone is in with regard to organ donation – further studies may be required to determine them |
| Cardinal 1995 | A stage of exercise scale was developed to differentiate between subjects classified into each of the transtheoretical model stages of change and tested in females | Develops survey instrument for testing | Several measures that might impact stages of change | Female adults, public awareness activity | Results showed that the scale was able to significantly and meaningfully differentiate between subjects classified by stage in terms of exercise energy expenditure, physical activity energy expenditure and other metabolic measures | The organ donation community may want to develop and rigorously test a similar type of scale for measuring the stages of change for organ donation |
| Cardinal 1995 | The study developed, evaluated, and compared two sets of written materials which promoted regular physical activity and fitness-promoting behaviors. | Review of materials to promote behavior change | Measured whether or not the materials were readable | Community, public awareness | No significant differences were observed between the two information packets; this could have been due to the small sample size. | One method for measuring public reaction to information on organ donation, but instruments would have to be further tested to see which results in actual behavior change. |
| Marcus 1994 | Review of studies which measure stages of change in relation to exercise behavior change | Review and theory | N/A | Community, public awareness activity | Applications of the transtheoretical model of the initiation, adoption, and maintenance of exercise behavior from clinical community, and public health perspectives are discussed | The transtheoretical theory of behavior change may also be applicable to organ donation |
| Occupational Health | ||||||
| Jeffery 1993 | An evaluation of a program that used tangible incentives to promote worksite health (specifically obesity and smoking cessation) | RCT – Quasi | Process measures of numbers of participating employees and one outcome measure of average weight loss | Community, public awareness activity | The power of the study was too small to determine differences between the incentive and non-incentive groups | One example of an attempt to conduct a randomized, controlled study in a naturalistic setting, and suggestions for improving study power |
| Kurtz 1997 | An evaluation of peer and professional trainers in a union-based occupational health and safety training program | Non-randomized controlled trial | Self-efficacy, outcome efficacy, and behavior | Community, trainer education program | Workers trained in health safety by their co-workers reported changing behavior more often than those workers trained by professional trainers | Intervention may be comparable to hospital-level interventions and organ donation education programs; this paper provides one type of evaluation model |
| Zwerling 1997 | Reviews evaluation strategies for programs to prevent occupational injury – notes that these kinds of evaluations could be improved and presents a hierarchy for improvement | Few RCTs are conducted – researchers should begin with qualitative studies and follow-up with simple quasi-experimental designs, then more complicated quasi-experimental designs, and RCTs when possible | Outcomes in reduced injury and intermediate outcomes of measurable events along the causal pathway | Worker education | Proposes a number of strategies to improve these evaluations while recognizing that RCTs may not be feasible due to difficulties of randomization, study groups contamination, and population turnover | Provides an overview of evaluation strategies in another behavioral health intervention field that may inform efforts to improve evaluations of organ donation activities |
| Other Conditions | ||||||
| Forst 1990 | A review of AIDS programs evaluations noting the lack of methodologically rigorous studies and the expense of longitudinal studies over time. | Discusses several evaluation options | Ouctome measures should include changes in knowledge, linked to attitude changes, linked to behavior changes – few studies achieve this | Community and targeted members | Some problems with the evaluations included: sites used only a post-test design to measure competency but no measure of change; tests were not standardized or compared across sites | Forst suggests areas for improvements in AIDS education evaluation studies; these programs face many similar difficulties as organ donation activity evaluation |
| Nonis 1996 | A survey was conducted of college students blood donors versus non-donors to identify attitudes and plan future studies | Framework study, No real intervention to change behaviors | Attitudes | College Students | Develops strategies for blood collection agencies to market to students | Blood donation is more closely related to organ donation than some of the other behavioral change activities—may provide a useful methodology for understanding organ donation tendencies |
| Evaluation Methods | ||||||
| Terrin 1997 | Paper evaluates the three important approaches to evaluating lifestyle and health outcomes: observational studies, individual subject random assignment trials, and community random assignment trials | Methods paper for community-level interventions Observational Studies, individual subject random assignment, and community random assignment | Lifestyle and health outcomes | Community-level interventions | Community randomized trials may be the best way to decide such public health policy issues as whether or not to use a community-wide anti-smoking program | Community randomization may also be a good method for evaluating organ donation activities, particularly public awareness campaigns |
| Stampfer 1997 | A methods paper discussing how and why large randomized clinical trials may not be feasible in evaluating the health effects of behavioral change, but rather how large-scale observational studies might provide useful information | Methods paper for evaluating the health effects of behavioral change; Randomized trials versus large-scale observational studies | Health effects | Community-level interventions | Due to limitations of using RCTs to evaluate health behavior change, observational studies continue to provide useful information | Evaluations of organ donation activities face similar constraints as health behavior promotion activities; this paper describes options for study design that may help to improve the rigor of studies while not making them infeasible |
| Green 1995 | Paper outlines an approach for the design and analysis of RCTs investigating community-based interventions for behavioral change aimed at health promotion | Approach to community-matched trials. 11 matched pairs of communities, randomized at community level, number of communities determines power | Outcome of smoking cessation | Community-level smoking cessation trial | Approach outlined helps improve the rigorousness and robustness of methods for evaluating the effects of community interventions | Similar types of community interventions are employed in the organ donation world; this methodology and the suggested ways to improve study design could prove useful – particularly with regard to matching pairs of communities for intervention versus control |
| Guiffrida 1997 | Reviewed randomized trials that tested the use of financial incentives to enhance patient compliance | Review of other RCTs | Compliance | Patient-level intervention, financial incentives | Financial incentives can improve patient compliance with medical advice | As the use of financial incentives has been suggested as a means of increasing organ donation, this paper provides references for other financial incentive |
B. Health Behavior Change References
Mammography / Cancer Screening
Campbell E, Rogers J, et al. Encouraging underscreened women to have cervical cancer screening: the effectiveness of a computer strategy. Prev Med. 1997; 26(6): 801-7.
Champion V, Huster G. Effect of interventions on stage of mammography adoption. J Behav Med. 1995; 18(2): 169-87.
Mayer-Oakes SA, Schweitzer SO, et al. Mammography use in older women with regular physicians: what are the predictors? Am J Prev Med. 1996; 12(1): 44-50.
Rakowski W, Woolverton H, et al. Integrating pros and cons for mammography and Pap testing: extending the construct of decisional balance to two behaviors. Prev Med. 1997; 26(5 pt. 1): 664-73
Rakowski W, Dube CE, et al. Assessing Elements of Women’s Decisions About Mammography. Health Psychology. 1992; 11(2): 111-118.
Savage SA, Clarke VA. Factors associated with screening mammography and breast-self examination intentions. Health Educ Res. 1996; 11(4): 409-21.
Scammon DL, Beard T. The role of "free" mammograms in motivating first-time screening: a community experiment. J Ambul Care Mark. 1995; 6(1): 59-71.
Strickland CJ, Meyskens FL, et al. Improving breast self-examination compliance: a Southwest Oncology Group randomized trial of three interventions. Prev Med. 1997; 26(3): 320-32.
Worden JK, Mickey RM, et al. Development of a Community Breast Screening Promotion Program Using Baseline Data. Preventive Medicine 1994; 23: 267-75.
Smoking/ Substance Abuse Prevention and Treatment
Lando HA, Hellerstedt WL, et al. Results of a long-term community smoking cessation contest. Am J Health Promot. 1991; 5(6): 420-5.
Popham WJ, Potter LD, et al. Effectiveness of the California 1990-1991 Tobacco Education Media Campaign. Am J Prev Med. 1994; 10(6): 319-326.
Popham WJ, Potter LD, et al. Do Anti-Smoking Media Campaigns Help Smokers Quit? Public Health Reports. 1993; 180(4): 510 – 513.
Prochaska JO, DiClemente CC, Norcross JC. In Search of How People Change: Applications to Addictive Behaviors. American Psychologist. 1992; 47(9): 1102-1114.
Werch CE, DiClemente CC. A multi-component stage model for matching drug prevention strategies and messages to youth stage of use. Health Educ Res. 1994; 9(1): 37-46.
Obesity / Physical Activity
Calfas KJ, French M, et al. Mediators of change in physical activity following an intervention in primary care: PACE. Prev Med. 1997; 26(3): 297-304.
Cardinal BJ. Development and evaluation of stage-matched written materials about lifestyle and structured physical activity, Percept Mot Skills, Apr-95, 80, 2, 543-6
Cardinal The stages of exercise scale and the stages of exercise behavior in female adults. J Sports Med Phys Fitness. 1995; 35(2): 87-92.
Fontaine KR, Cheskin LJ. Self-efficacy, attendance, and weight loss in obesity treatment. Addict Behav. 1997; 22(4): 567-70.
Laitakari J, Oja P, et al. Is long-term maintenance of health-related physical activity possible? An analysis of concepts and evidence. Health Educ Res. 1996; 11(4): 463-77.
Marcus BH, Dube CE, et al. Training physicians to conduct physical activity counseling. Prev Med. 1997; 26(3): 382-8.
Marcus BH, Selby VC, et al. Self-efficacy and the Stages of Exercise Behavior Change. Research Quarterly for Exercise and Sport. 1992; 63(1): 60-66.
Marcus BH, Simkin LR. The transtheoretical model: applications to exercise behavior. Medicine and Science in Sports and Exercise. 1994; 26(11): 1400-1404.
Potvin L, Nguyen NM, et al. Prevalence of stages of change for physical activity in rural, suburban, and inner-city communities. J Community Health 1997; 22(1): 1-13.
Sellers DE, Crawford SL, et al. Understanding the variability in the effectiveness of community heart health program: A meta-analysis. Soc. Sci. Med. 1997; 44(9): 1325-1339.
Stone EJ. Can School Health Education Programs Make a Difference? Preventive Medicine 1996; 25: 54-55.
Occupational Health
Jeffrey RW, Kelder SH, et al. An empirical evaluation of the effectiveness of tangible incentives in increasing participation and behavior change in a worksite health promotion program. Am J Health Promot. 1993; 8(2): 98-100.
Kurtz JR, Schork MA, et al. An evaluation of peer and professional trainers in a union-based occupational health and safety training program. J Occup Environ Med. 1997; 39(7): 661-71.
Zwerling C, Daltroy LH, et al. Design and Conduct of Occupational Injury Intervention Studies: A Review of Evaluation Strategies. American Journal of Industrial Medicine. 1997; 32: 164-179.
Other Health Behavior Activity Evaluations
Forst M, Jang M, et al. Issues in the evaluation of AIDS education programs. The case of California. Eval Health Prof. 1990; 13(2): 147-67.
Guiffrida A, Torgerson DJ. Should we pay the patient? Review of financial incentives to enhance patient compliance. BMJ 1997; 315(7110): 703-7.
Nonis SA, Hudson G, et al. College student's blood donation behavior: relationships to demographics, perceived risk and incentives. Health Mark Q. 1996; 13(4): 33-46.
Pinch WJ, Barr P, et al. Implementation of the Patient Self-Determination Act: a survey of Nebraska hospitals. Res Nurs Health 1995; 18(1): 59-66.
Sellers DE, McKinlay JB, et al. Understanding the variability in the effectiveness of community heart health programs: a meta-analysis. Soc Sci Med. 1997; 44(9): 1325-39.
Stone EJ. Can school health education programs make a difference? Prev Med. 1996; 25(1): 54-5.
Volmink J, Garner P. Systematic review of randomized controlled trials of strategies to promote adherence to tuberculosis treatment. BMJ 1997; 315(7120): 1403-6.
Evaluation Methods
Green SB, Lynn WR, et al. Interplay between design and analysis for behavioral intervention trials with community as the unit of randomization. Am J Epidemiol 1995; 142(6): 587-93.
Green, SB. The advantages of community-randomized trials for evaluating lifestyle modification. Control Clin Trials. 1997; 18(6): 506-13.
Rodes F, Reis J, et al. Using behavioral theory in computer-based health promotion and appraisal. Health Educ Behav. 1997; 24(1): 20-34.
Hanson CL, Kolterman OG, et al. Empirical validation for a family-centered model of care. Diabetes Care 1995; 18(10): 1347-56.
Stampfer, M. Observational epidemiology is the preferred means of evaluating effects of behavioral and lifestyle modification. Control Clin Trials 1997; 18(6): 494 - 9.
Terrin, ML. Individual subject random assignment is the preferred means of evaluating behavioral lifestyle modification. Control Clin Trials 1997; 18(6): 500-5, 514-6.
Velicer WF, Prochaska JO. A criterion measurement model for health behavior change. Addict Behav. 1996; 21(5): 555-84.